
Kodluyoruz olarak, ülkemizi yapay zekâ alanına hazırlamak üzere bu yıl Ankara ve İstanbul’da tam 5 bootcamp hayata geçirdik, 150 genci geleceğin veri bilimcileri olmaları için hazırladık.
Hayata geçirdiğimiz Uygulamalı Veri Bilimi ve Makine Öğrenmesi bootcamp’leri Türkiye’de bir ilk oldu. Gençlerin bu eğitimlerden mezun olabilmeleri için bir proje geliştirmeleri gerekliydi. Aşağıda, yapılan projelerden örnekleri paylaşıyoruz. Amacımız veri bilimi ve makine öğrenmesine giriş yapmak isteyen herkesin gerçek hayatta neler yapabileceklerini görüp ilham almaları.
Projeleri gerçekleştiren mezunlarımıza ve onlara yön veren Kodluyoruz eğitmenlerini tebrik ediyoruz!
Proje #1: Derin Öğrenme ve Makine Öğrenmesi ile Yüzde Anlık olarak Duygu Tespiti
Proje sahipleri: Berk Sudan, İrem Şahin
Amaç: İnsan yüzünde oluşan birçok farklı duygu durumunu anında ve doğru tespit edebilmek.
Proje: Binden fazla fotoğrafın bulunduğu Cohn-Kanade veri setindeki fotoğraflar, Berk ve İrem’in yazdığı veri hazırlama modülü ile çekilip etiketlenerek etiketli veri seti oluşturuldu. Bu veri setinde 398 yüz fotoğrafı ve 8 adet duygu etiketi (nötr, kızgın, kibirli, iğrenme, korku, mutluluk, üzüntü ve şaşırma) bulunmakta. Sonra, her yüz fotoğrafından Keras’ın pre-trained (önceden eğitilmiş) vggface modeli kullanılarak yüz ifadesini gösteren 68 nokta çıkarıldı. Noktalar aşağıdaki görselde gözükmekte:

Her yüzden aynı sayıda (68 adet) nokta çıkarıldığı ve yüzler bu noktalar aracılığıyla karşılaştırılabildi. Şu an elimizde 68 nokta * 2 (x ve y eksen değerleri), yani 136 adet değer var. Bu değerlerin karşılaştırılması ve buradan sınıflandırma yapılması, düşük bir başarı oranına sahip; çünkü koordinat değerleri yüzün büyüklüğüne ve biçimine göre değişiklik gösterebiliyor. Bu yüzden, 68 noktadan en merkezindeki nokta, sıfır noktası (orijin) olarak belirlenip diğer tüm noktalar bu sıfır noktasına göre vektörel şekilde ifade edildi. Böylece (68 – 1) * 4 (x, y, uzunluk, açı) = 268 adet öz nitelik çıkarıldı. Özniteliklere karşılık gelen sınıf değerleri veri setinden makine öğrenmesi modelleriyle öğrenildi ve bilgisayarın kamerasından OpenCV kütüphanesi aracılığıyla periyodik olarak alınan resimlerden anlık olarak etiketleme yapıldı.
Bu anlık etiketleme aşağıdaki görseldeki gibi:

Başarı Oranı: Kullanılan SVM, Random Forest, Gradient Boosting ve Naïve Bayes makine öğrenmesi algoritmalarıyla sonuç görseldeki gibidir:
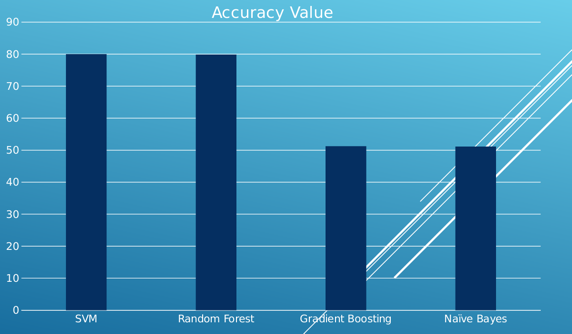
Diğer bir deyişle, SVM ve Random Forest algoritmalarıyla 8 adet duygu etiketi için yaklaşık %80 başarı oranı elde edilmiştir.
Kullanılan veri seti: Cohn-Kanade (CK and CK+) Database
Proje #2: EEG Sinyallerinden Epilepsi Hastalığı Tespiti
Proje sahipleri: Elif Nur Korkmaz, Nur Aslıhan Karaman
Amaç: EEG Sinyallerinin veri bilimi ve çeşitli makine öğrenmesi yöntemleriyle işlenerek kişinin epilepsi hastası olup olmadığının tahmin edilmesi.
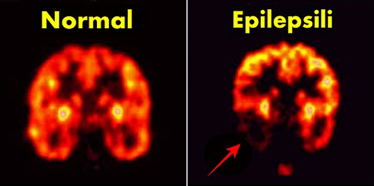
Proje: “Sara hastalığı” olarak da bilinen epilepsi, kısa süreli beyin fonksiyon bozukluğuna bağlıdır ve beyin hücrelerinde geçici anormal elektrik yayılması sonucu ortaya çıkar. Epilepsi, dünya nüfusunun yaklaşık %1’ini etkileyen bir hastalıktır.
Hastalığın erken tanısı ve doğru teşhisine katkı sağlamak için veri bilimi ve çeşitli makine öğrenmesi metotları kullanılabilir. Bunun için, Elif Nur ve Nur Aslıhan bir araya gelerek epilepsi hastası olan ve olmayan kişilerden kaydedilen beyin dalgaları aktivitesini elektriksel ölçen EEG sinyallerini işleyerek hastanın epilepsi hastası olup olmadığını tahmin eden bir model geliştirdi.
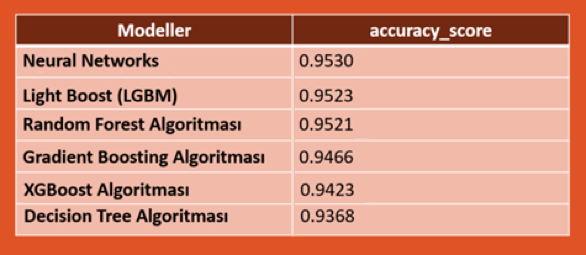
Başarı oranı: Birçok makine öğrenmesi modelinden yararlanan projede, ‘accuracy’, ‘precision’ ve ‘recall’ değerleri göz önünde bulundurularak en iyi sonuç veren Random Forest modeli seçildi. Bu modele göre tahmin başarısı oranı %95’in üzerinde. Kullanılan tüm modellerin sonuçları aşağıda.
Proje #3: Mobil Oyunlarda Kullanıcıların Ulaşabileceği Seviye Tahmini
Proje sahipleri: Ayşe Akca, Hatice Candan, İzel Ergu
Amaç: Kullanıcının oyundaki davranışına göre 7. seviyeye (‘level’) ulaşıp ulaşamayacağını ve kullanıcı oyunu daha ilk indirdiği anda nasıl bir profil izleyeceğini tahmin etmek.
Proje: Proje, bu amaca yönelik olarak oyun kullanıcılarına ait 16 milyonluk bir veri seti kullandı. Kodluyoruz’un üç öğrencisi, bu 16 milyonluk veri setinde 23.362 farklı kullanıcıya ait olan verileri Python’da makine öğrenmesi algoritmaları için uygun hale getirmekle işe başladılar. Bunun için SQLite veri tabanı yönetim sistemi üzerinde kullanıcı bazlı işlemler yaparak 16 milyonluk veri setini 23.362’ye düşürerek veri tabanı oluşturdular. Oluşturdukları bu veri tabanı hem işlenebilir hem de Python’da algoritmalara sokulur hale gelmiş oldu. Kullanıcının “7. level” seviyesine erişip erişemeyeceğini tahmin etmek için sayısal değişkenlerle modelleme yaparken, oyunu ilk indirdiği andaki davranışını tahmin etmek için kategorik değişkenlerle modelleme yaptılar.
Başarı Oranı: Modellemede Random Forest algoritması kullanılarak kullanıcının “7. level” seviyesine gelip gelemeyeceğinin tahmini %98,1 oranında başarı göstermiştir. Aynı şekilde Random Forest algoritması kullanılarak kullanıcının oyunu indirdiği ilk anda 7. level seviyesine gelip gelemeyeceğinin tahmini ise %67,4 oranında başarı göstermiştir.
Kullanılan veri seti: Kullanılan veri seti, Kodluyoruz eğitmeni olan Damla Dokuzoğlu tarafından sağlanmış olup, açık bir veri seti değildir.
Proje #4: Google PlayStore’da Bulunan Uygulamaların Yıldız Tahmini
Proje sahipleri: Özlem Aslan, Eray Demir
Amaç: Google Playstore’da bulunan uygulamaların ne kadar yıldız alacağını ve uygulamalara yapılan yorumların içinde en çok geçen kelimeleri tahmin etmeye çalışmak.
Proje: Projede 34.000 adet uygulamanın bulunduğu bir veri seti, çeşitli makine öğrenmesi algoritmalarında değerlendirildi. Aynı zamanda, uygulamalara yapılan yorumlar pozitif, negatif, tarafsız olarak sınıflandırıldı ve NLP kullanılarak bu yorumların içinde en fazla geçen kelimeler bulundu.
Başarı oranı: Hem yıldız hem de yorum tahminini en iyi yapan model, sırasıyla %79 ve %87 başarı oranıyla Random Forest modeli oldu.
Veri seti: https://www.kaggle.com/lava18/google-play-store-apps
Referanslar:
– Kanade, T., Cohn, J. F., & Tian, Y. (2000). Comprehensive database for facial expression analysis. Proceedings of the Fourth IEEE International Conference on Automatic Face and Gesture Recognition (FG’00), Grenoble, France, 46-53.
– Lucey, P., Cohn, J. F., Kanade, T., Saragih, J., Ambadar, Z., & Matthews, I. (2010). The Extended Cohn-Kanade Dataset (CK+): A complete expression dataset for action unit and emotion-specified expression. Proceedings of the Third International Workshop on CVPR for Human Communicative Behavior Analysis (CVPR4HB 2010), San Francisco, USA, 94-101.